
 En un post anterior mencionaba la manera de crear un enlace que nos permitiera compartir contenido directamente en nuestras redes sociales. Vemos a continuación como poner una barra social dentro de nuestro post y poder compartir el artículo actual muy fácilmente, que además como agregado tiene la funcionalidad de guardar nuestro post no solo en nuestro servidor, sino en uno externo.
En un post anterior mencionaba la manera de crear un enlace que nos permitiera compartir contenido directamente en nuestras redes sociales. Vemos a continuación como poner una barra social dentro de nuestro post y poder compartir el artículo actual muy fácilmente, que además como agregado tiene la funcionalidad de guardar nuestro post no solo en nuestro servidor, sino en uno externo.
Existen multitudes de servicios web que nos permiten crear una página web o un blog (o lo que gustemos) completamente gratis o pagando cierta cantidad. Toda nuestra información esta ahí, pero, ¿que pasaría si ese servicio web desaparece de pronto llevándose todos nuestros trabajos?, bueno, es cierto que siempre debemos hacer copias de seguridad de nuestros trabajos, pero a veces se nos olvida. Es por eso que existen algunos servicios que ofrecen una versión histórica de nuestros sitios web sin tener que hacer, solo tener paciencia y esperar a que lo indexen de vez en cuando, vamos como funciona esto.
Antes que nada hay que aclarar que estos servicios solo ofrecen un respaldo de vez en cuando, no tendremos un respaldo diario ni de cada post (a no ser que lo programemos y diremos como mientras redactamos este artículo), tampoco podremos acceder a nuestro sitio web desaparecido y tampoco tendremos acceso al código fuente del artículo si lo hemos redactado en php o asp. Solo veremos una copia tal y como la ven nuestros visitantes.
Bien. El primer portal del que voy a hablar es Wayback Machine, el cual se encuentra en la dirección https://archive.org/web/. Este servicio web va creando una copia entera de nuestro sitio web cada cierto tiempo, esta muy bien porque he encontrado sitios web enteros (o casi enteros) que desaparecieron incluso hace una década atrás (como un sitio web personal que tuvimos hace tiempo y que ya no fue posible mantener). El problema es que no se indexa todo el sitio web entero a veces, en ocasiones solo indexa páginas sueltas de nuestro portal, se supone debería pasar al siguiente enlace y seguir armando nuestro sitio web pero por alguna razón se detiene. Tampoco funciona con blogger, solo he visto en el caso de este blog que se ha indexado la página principal cada cierto tiempo, pero los artículos individuales no están (o por lo menos faltan muchos, es posible agregarlos manualmente, en un momento explicaré como).
El segundo servicio es archive.today cuya dirección web es https://archive.ph/; es muy similar a Wayback Machine. Básicamente consiste también en una araña web que pasa cada cierto tiempo por nuestro portal web y va agregando nuestras páginas web sueltas y con ello reconstruye una copia entera de nuestro sitio web. Sin embargo hay un detalle en comparación con Wayback Machine.
Vamos a ver un ejemplo como trabajan los dos, para ello en nuestro navegador web escribiremos la dirección web de Wayback Machine (https://archive.org/web/) y presionaremos ENTER en la barra de navegación, esto nos llevará a una página web como la siguiente:

En el área de búsqueda escribiremos http://marjuanm.blogspot.com y presionaremos el botón "BROWSE HISTORY", esperaremos a que carguen los resultados.
Ahora veremos una barra de tiempo donde nos indica los años que han sido indexados desde nuestro sitio web y un calendario con los meses del ultimo año en cuestión, así como una serie de puntos en color azul indicandonos en que fecha ha pasado la araña web por nuestro portal y a agregado contenido a las base de datos de Wayback Machine.
Al momento de la redacción de éste artículo la última revisión fue el 21 de noviembre de 2018, presionaremos el botón azul sobre la fecha (nos muestra una pantalla previamente informándonos que ese día solo hizo una captura) y a continuación seremos direccionados a la copia web de nuestro sitio web que corresponde al 21 de noviembre de 2018. Así lucía nuestro blog a esa fecha.

Como podemos ver faltan los artículos más recientes, es normal, es una copia antigua. Ahora presionaremos el enlace "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web" y como no está indexado el artículo veremos el siguiente mensaje:

Ahora presionamos el enlace "Click here to search for all archived pages under http://marjuanm.blogspot.com/2018/09/" veremos que efectivamente no hay ningún artículo enlazado para el septiembre de 2018 (la fecha del artículo es del 11 de septiembre de 2018).

Pero no hay problema, mientras el portal web a indexar exista podemos agregar manualmente todas las páginas sueltas que queramos y así tener una copia (aunque sea parcial) de nuestro blog o cualquier otro tipo de portal web en la red y que se conserve tal cual por muchos años. Presionaremos el enlace "Save this url in the Wayback Machine" para agregar ese artículo al historial de Wayback machine".

Ahora si, si volvemos a revisar el historial de nuestra web para el 21 de noviembre y de nuevo hacemos clic sobre el artículo "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web" ahora si veremos nuestro artículo viniendo directamente desde el servidor de Wayback machine, es todo, ya formamos parte de la historia jejeje.

Veamos como funciona archive.today. Igualmente como en el caso de Wayback machine iremos a nuestro navegador web e ingresaremos el url https://archive.ph/ y presionaremos ENTER, veremos una página web como la siguiente:

Si lo deseamos podemos agregar directamente un sitio web o un artículo suelto a la base de datos de archive.today o podemos ver que ha indexado, iremos por esta opción: ingresaremos en la segunda área de búsqueda el URL de nuestro blog y presionaremos el botón "Buscar".

La verdad es que los resultados son bastante decepcionantes, solo dos veces la araña web ha pasado por el blog y siendo la segunda vez que yo agregué artículos porque solo había unos pocos, así que no es muy confiable como Wayback machine que por lo menos pasa cada tres meses, aquí estamos hablando de tres años de diferencia. Bueno, no nos desanimemos, lo bueno es que al igual que su contraparte también podemos agregar manualmente nuestras páginas sueltas e ir construyendo el historial.
Haremos clic en la versión más reciente que corresponde al 11 de diciembre de 2018, así lucía nuestro blog para esa fecha:

Si presionamos el enlace "Todas las instantáneas del host marjuanm.blogspot.com" veremos que se ha indexado de nuestro sitio web.

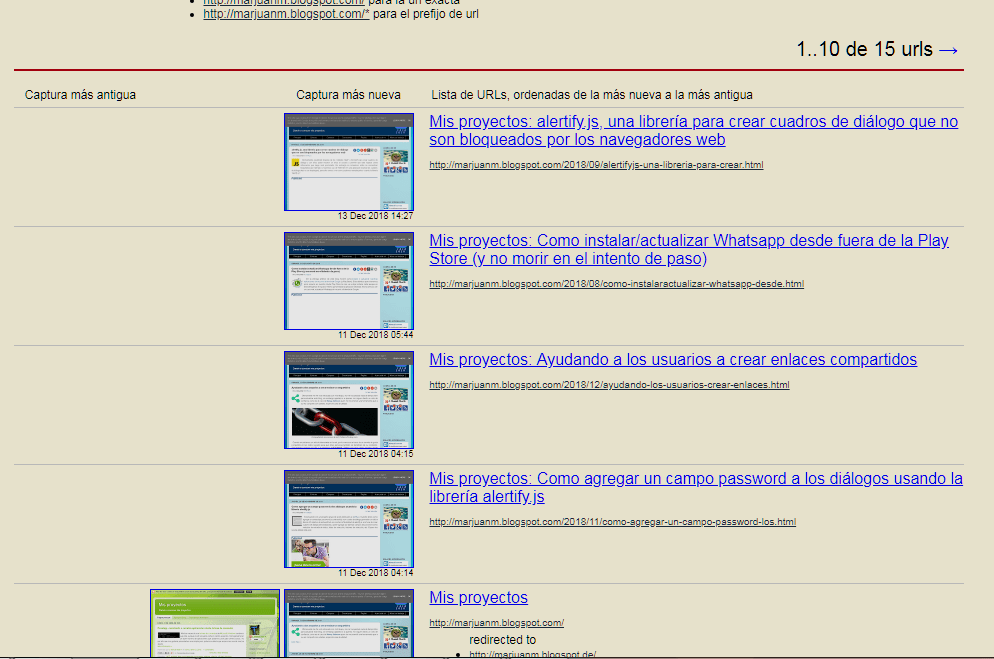
Solo catorce documentos indexados, repito, pasa muy pocas veces por lo que deja mucho que desear, regresaremos a nuestra web principal con el botón "Atrás" de nuestro navegador web y haremos clic sobre el mismo artículo "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web".
OOPS!!!!, archive.today no nos direcciona a la versión archivada sinó al artículo del blog directamente, ¿y porqué es esto?, pues porque no se encuentra en su base de datos y en lugar de ello nos direcciona al artículo directamente, pero nosotros queremos ver como se veía el artículo para esa fecha (11 de septiembre de 2018) y si no está indexarlo, ¿cómo podemos hacerlo?.
Abriremos en nueva pestaña o ventana del navegador la dirección web https://archive.ph/ y en la primer área de búsqueda ingresaremos el URL a indexar (http://marjuanm.blogspot.com/2018/09/alertifyjs-una-libreria-para-crear.html) y presionaremos el botón "Archivar".
Veremos una pantalla como la siguiente, archive.today está indexando ese artículo y a continuación nos enviará al archivo ya indexado.

De nuevo, ya somos parte de la historia. Ahora iremos a ver todo el histórico de nuestro sitio web:


Como podemos ver, ya nuestro artículo forma parte de archive.today, el problema es que el indexado automático es extremadamente lento, prácticamente tendremos que ir agregando los artículos uno por uno (Wayback machine también tiene ese problema), además en comparación con Wayback machine no podremos agregar los artículos faltantes al vuelo, sinó que hay que ir a la página web del proyecto e irlos anexando.
Ahora que entendemos como trabajan estos dos servicios vamos a ver la manera de agilizar el indexado de los mismos.
El siguiente script nos permitirá agregar una barra social a nuestros artículos, permitiendo que los navegantes si les gustó lo compartan en las redes sociales o lo agreguen al histórico de Wayback machine o archive.today y así el artículo se conserve para siempre (o por lo menos mientras existan dichos servicios), aunque en lo personal pienso que es mejor nosotros mismos una vez redactado el artículo solicitar el indexado.
Una vez ya redactado nuestro artículo cambiaremos a la vista HTML del mismo (esto puede variar dependiendo del sistema de blog que tengamos, en el caso de un servidor ya lo integró a la plantilla de blogger por lo que aparece automáticamente para todos los post) y donde queramos que aparezca la barra social escribiremos lo siguiente:
<table border='0'>
<tr>
<td valign='top'><a href='#' onclick='window.open('https://www.facebook.com/sharer/sharer.php?u=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Share on Facebook'><img alt='Share on Facebook' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Facebook.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://twitter.com/intent/tweet?text=' + encodeURIComponent(document.title) + ':%20' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Tweet'><img alt='Tweet' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Twitter.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://plus.google.com/share?url=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Share on Google+'><img alt='Share on Google+' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Google+.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('http://www.reddit.com/submit?url=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Submit to Reddit'><img alt='Submit to Reddit' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Reddit.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://web.archive.org/save/' + document.URL); return false;' target='_blank' title='Submit to Internet archive'><img alt='Submit to Internet archive' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/archive.jpg' width='24'/></a></td>
<td valign='top'><a href='#' onclick='javascript:addtoarchive(); return false;' title='Submit to archive.today'><img alt='Submit to archive.today' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/archive.png' width='24'/></a></td>
<td valign='top'><a href='mailto:?body=Dando%20a%20conocer%20mis%20proyectos:%20http%3A%2F%2Fmarjuanm.blogspot.mx' target='_blank'><img alt='Send email' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Email.png' width='24'/></a></td>
</tr>
<tr>
<td align='right' colspan='5' valign='top'>
<a href='https://simplesharingbuttons.com/' target='_blank'><font style='font-size: 8px;'>Por Simple Sharing Buttons</font></a>
</td>
</tr>
</table>
<script language='JavaScript'>
function addtoarchive()
{
document.archive.url.value = document.URL;
document.archive.submit();
}
</script>
<form action='https://archive.ph/submit/' method='post' name='archive' style='display: inline;' target='_blank'>
<input name='url' type='hidden' value=''/>
</form>
El funcionamiento es bastante simple, es una tabla donde cada celda representa un servicio que nos permitirá compartir el enlace, siendo el orden el siguiente:
Mediante el parámetro document.URL pasaremos el URL o dirección del artículo actual, por lo que funcionará para cualquier artículo donde lo coloquemos, como opcional algunos servicios nos permiten agregarle un título personalizado al artículo a compartir, usaremos document.title para ello en el formato del enlace para usarse.
Sin embargo a diferencia de los servicios anteriores, archive.today no pasa el URL a indexar por el método GET, es decir formando parte del enlace que bien pudiera copiarse y pegarse en el navegador web, sinó por el método POST, por lo que hay que integrar un formulario oculto en el script, llenarlo al presionar el botón compartir y luego enviarlo mediante una función JavaScript.
<script language='JavaScript'>
function addtoarchive()
{
document.archive.url.value = document.URL;
document.archive.submit();
}
</script>
Dicha función rellena el campo "url" del formulario con el URL del artículo a compartir y luego envía el contenido del formulario.
<form action='https://archive.ph/submit/' method='post' name='archive' style='display: inline;' target='_blank'>
<input name='url' type='hidden' value=''/>
</form>
Así podemos hacer que los artículos compartidos se anexen a la base de datos de archive.today. Ahora vamos a verlo en acción:
Cuando ya tenemos nuestra barra social esta lucirá de la siguiente manera:

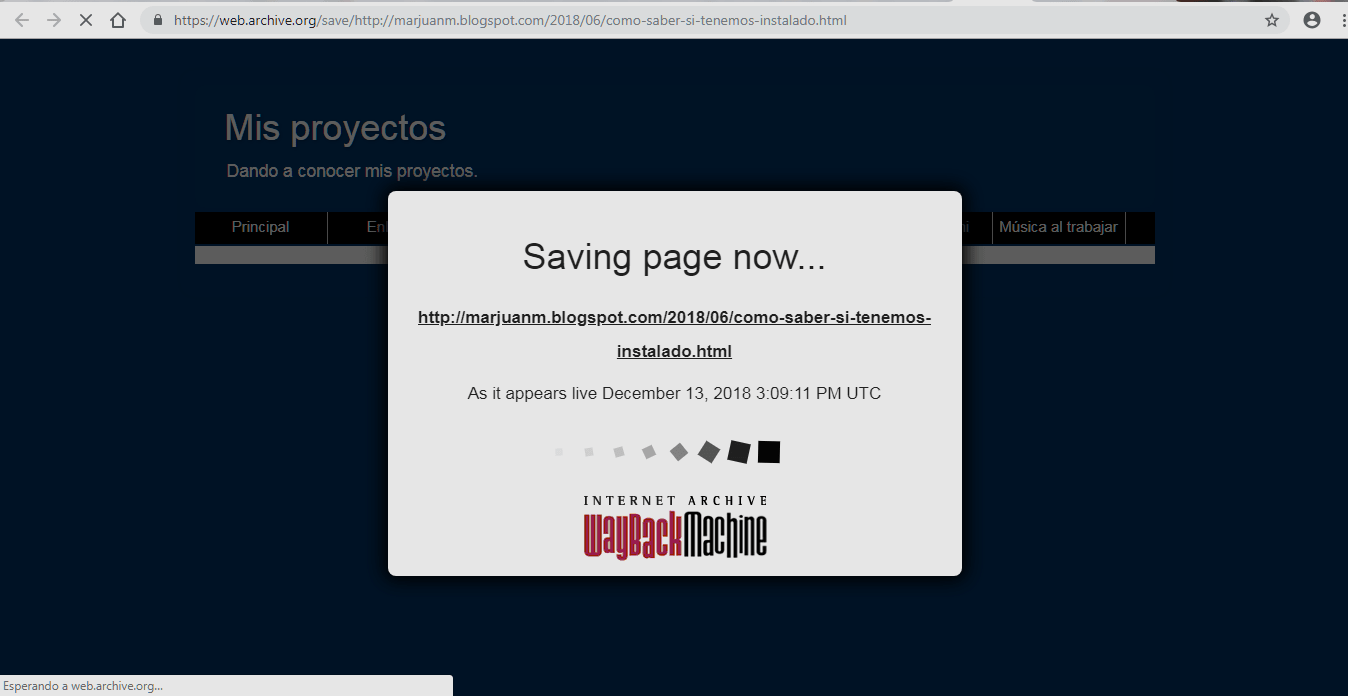
Abriremos un artículo de nuestro blog que se supone no está indexado en ninguno de los dos servicios, en este caso es el artículo "Como saber si tenemos instalado Microsoft Office usando VB.Net" http://marjuanm.blogspot.com/2018/06/como-saber-si-tenemos-instalado.html.
Presionaremos el botón agregar que corresponde al servicio de Wayback machine, se abrirá una nueva página web donde el servicio nos confirma que está agregando nuestro artículo a su base de datos. Es todo, ya tenemos ese artículo indexado.

Haremos lo mismo con archive.today. Presionaremos el botón que corresponde a este servicio, una vez presionado veremos la confirmación de que nuestro artículo está siendo indexado.

Ya está, ya nuestro artículo forma parte de la base de datos de archive.today y cuando visitemos el archivo histórico debe visualizarse (desde archive.today no desde nuestro blog) sin problemas.
Antes que nada hay que aclarar que estos servicios solo ofrecen un respaldo de vez en cuando, no tendremos un respaldo diario ni de cada post (a no ser que lo programemos y diremos como mientras redactamos este artículo), tampoco podremos acceder a nuestro sitio web desaparecido y tampoco tendremos acceso al código fuente del artículo si lo hemos redactado en php o asp. Solo veremos una copia tal y como la ven nuestros visitantes.
Bien. El primer portal del que voy a hablar es Wayback Machine, el cual se encuentra en la dirección https://archive.org/web/. Este servicio web va creando una copia entera de nuestro sitio web cada cierto tiempo, esta muy bien porque he encontrado sitios web enteros (o casi enteros) que desaparecieron incluso hace una década atrás (como un sitio web personal que tuvimos hace tiempo y que ya no fue posible mantener). El problema es que no se indexa todo el sitio web entero a veces, en ocasiones solo indexa páginas sueltas de nuestro portal, se supone debería pasar al siguiente enlace y seguir armando nuestro sitio web pero por alguna razón se detiene. Tampoco funciona con blogger, solo he visto en el caso de este blog que se ha indexado la página principal cada cierto tiempo, pero los artículos individuales no están (o por lo menos faltan muchos, es posible agregarlos manualmente, en un momento explicaré como).
El segundo servicio es archive.today cuya dirección web es https://archive.ph/; es muy similar a Wayback Machine. Básicamente consiste también en una araña web que pasa cada cierto tiempo por nuestro portal web y va agregando nuestras páginas web sueltas y con ello reconstruye una copia entera de nuestro sitio web. Sin embargo hay un detalle en comparación con Wayback Machine.
Vamos a ver un ejemplo como trabajan los dos, para ello en nuestro navegador web escribiremos la dirección web de Wayback Machine (https://archive.org/web/) y presionaremos ENTER en la barra de navegación, esto nos llevará a una página web como la siguiente:

En el área de búsqueda escribiremos http://marjuanm.blogspot.com y presionaremos el botón "BROWSE HISTORY", esperaremos a que carguen los resultados.
Ahora veremos una barra de tiempo donde nos indica los años que han sido indexados desde nuestro sitio web y un calendario con los meses del ultimo año en cuestión, así como una serie de puntos en color azul indicandonos en que fecha ha pasado la araña web por nuestro portal y a agregado contenido a las base de datos de Wayback Machine.
Al momento de la redacción de éste artículo la última revisión fue el 21 de noviembre de 2018, presionaremos el botón azul sobre la fecha (nos muestra una pantalla previamente informándonos que ese día solo hizo una captura) y a continuación seremos direccionados a la copia web de nuestro sitio web que corresponde al 21 de noviembre de 2018. Así lucía nuestro blog a esa fecha.

Como podemos ver faltan los artículos más recientes, es normal, es una copia antigua. Ahora presionaremos el enlace "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web" y como no está indexado el artículo veremos el siguiente mensaje:
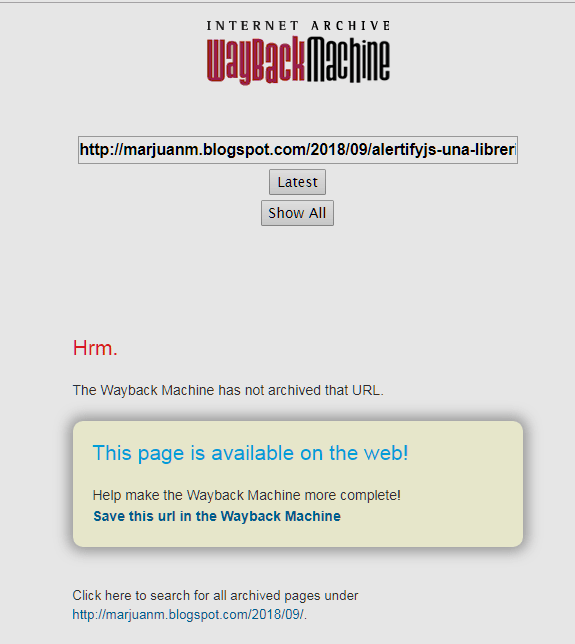
Ahora presionamos el enlace "Click here to search for all archived pages under http://marjuanm.blogspot.com/2018/09/" veremos que efectivamente no hay ningún artículo enlazado para el septiembre de 2018 (la fecha del artículo es del 11 de septiembre de 2018).
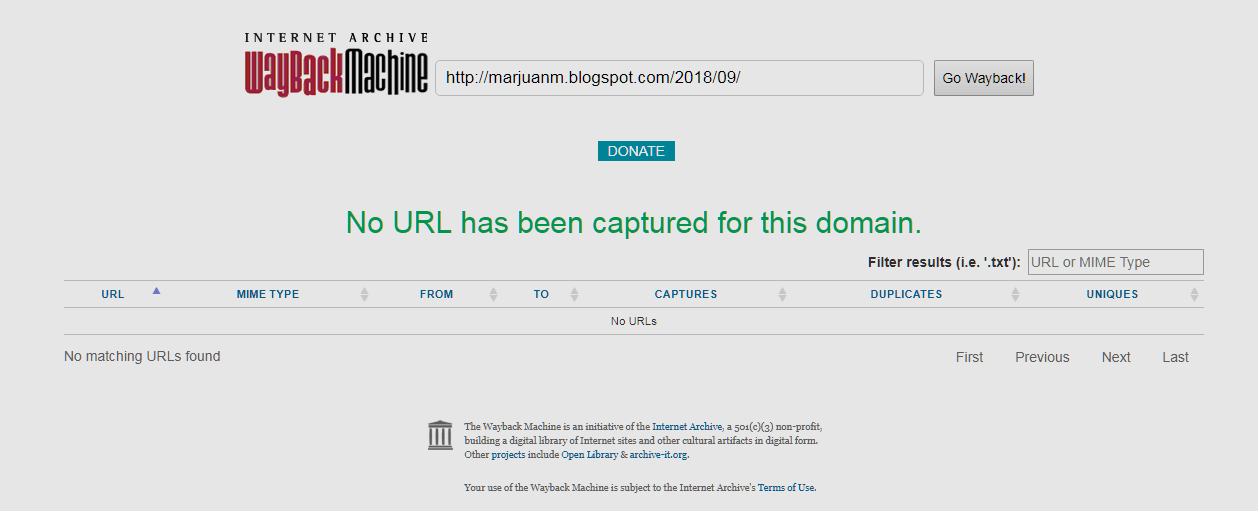
Pero no hay problema, mientras el portal web a indexar exista podemos agregar manualmente todas las páginas sueltas que queramos y así tener una copia (aunque sea parcial) de nuestro blog o cualquier otro tipo de portal web en la red y que se conserve tal cual por muchos años. Presionaremos el enlace "Save this url in the Wayback Machine" para agregar ese artículo al historial de Wayback machine".
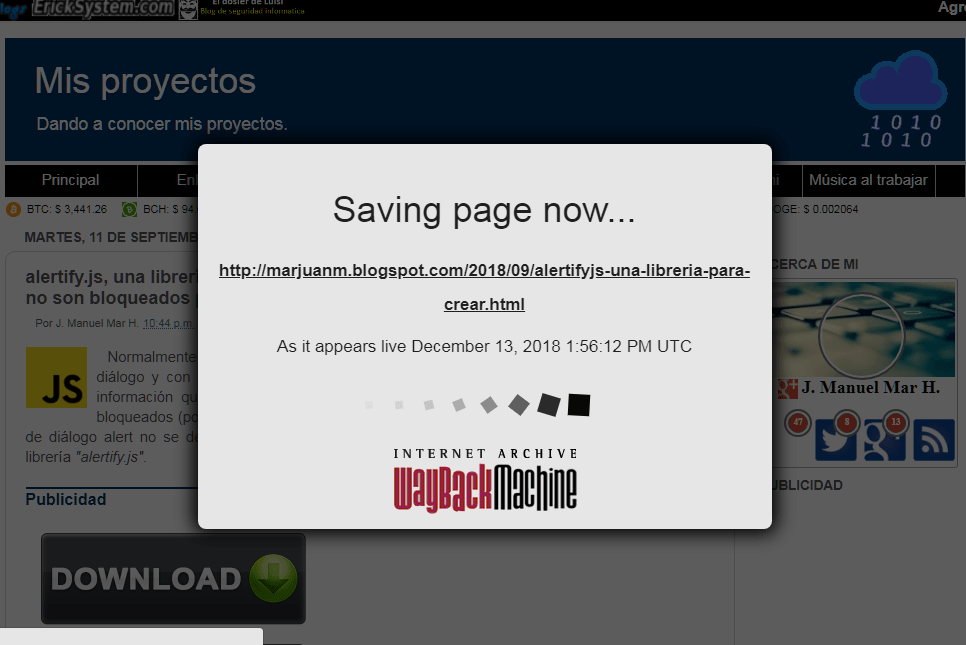
Ahora si, si volvemos a revisar el historial de nuestra web para el 21 de noviembre y de nuevo hacemos clic sobre el artículo "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web" ahora si veremos nuestro artículo viniendo directamente desde el servidor de Wayback machine, es todo, ya formamos parte de la historia jejeje.
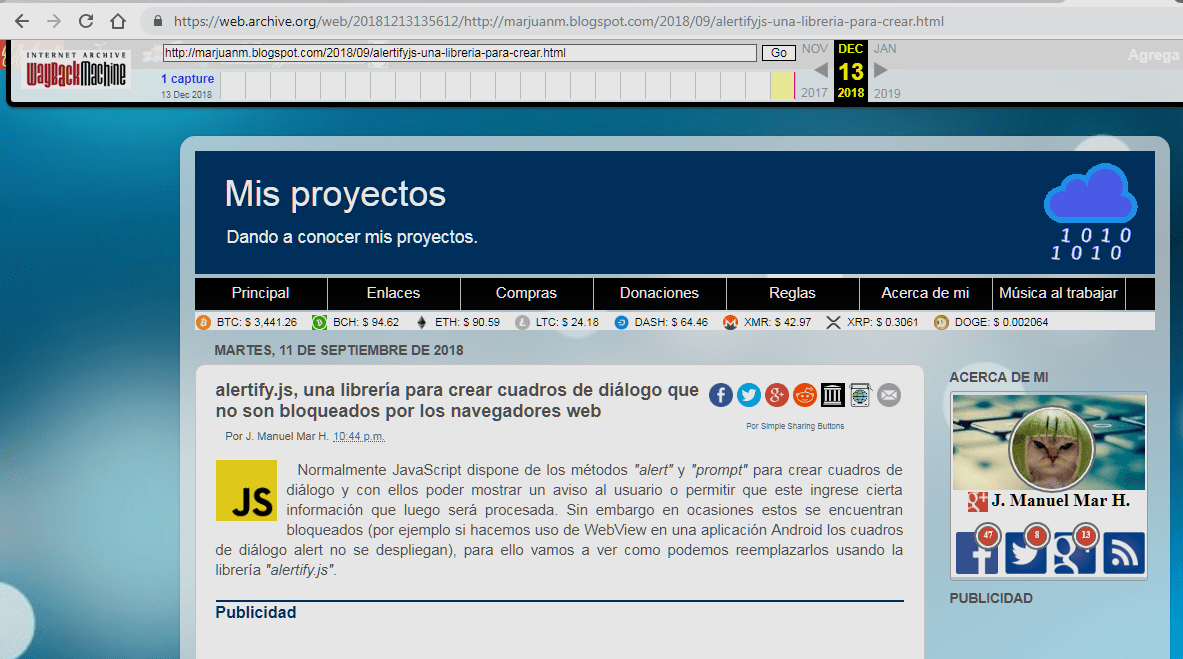
Veamos como funciona archive.today. Igualmente como en el caso de Wayback machine iremos a nuestro navegador web e ingresaremos el url https://archive.ph/ y presionaremos ENTER, veremos una página web como la siguiente:
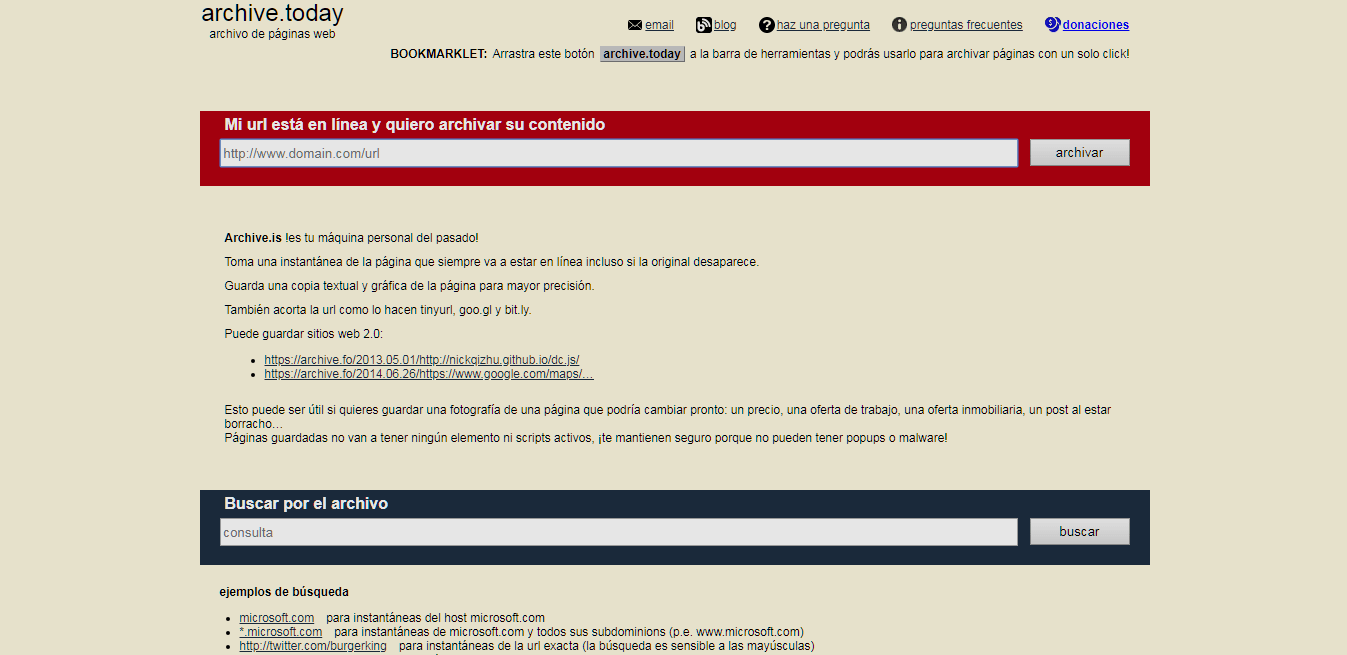
Si lo deseamos podemos agregar directamente un sitio web o un artículo suelto a la base de datos de archive.today o podemos ver que ha indexado, iremos por esta opción: ingresaremos en la segunda área de búsqueda el URL de nuestro blog y presionaremos el botón "Buscar".

La verdad es que los resultados son bastante decepcionantes, solo dos veces la araña web ha pasado por el blog y siendo la segunda vez que yo agregué artículos porque solo había unos pocos, así que no es muy confiable como Wayback machine que por lo menos pasa cada tres meses, aquí estamos hablando de tres años de diferencia. Bueno, no nos desanimemos, lo bueno es que al igual que su contraparte también podemos agregar manualmente nuestras páginas sueltas e ir construyendo el historial.
Haremos clic en la versión más reciente que corresponde al 11 de diciembre de 2018, así lucía nuestro blog para esa fecha:
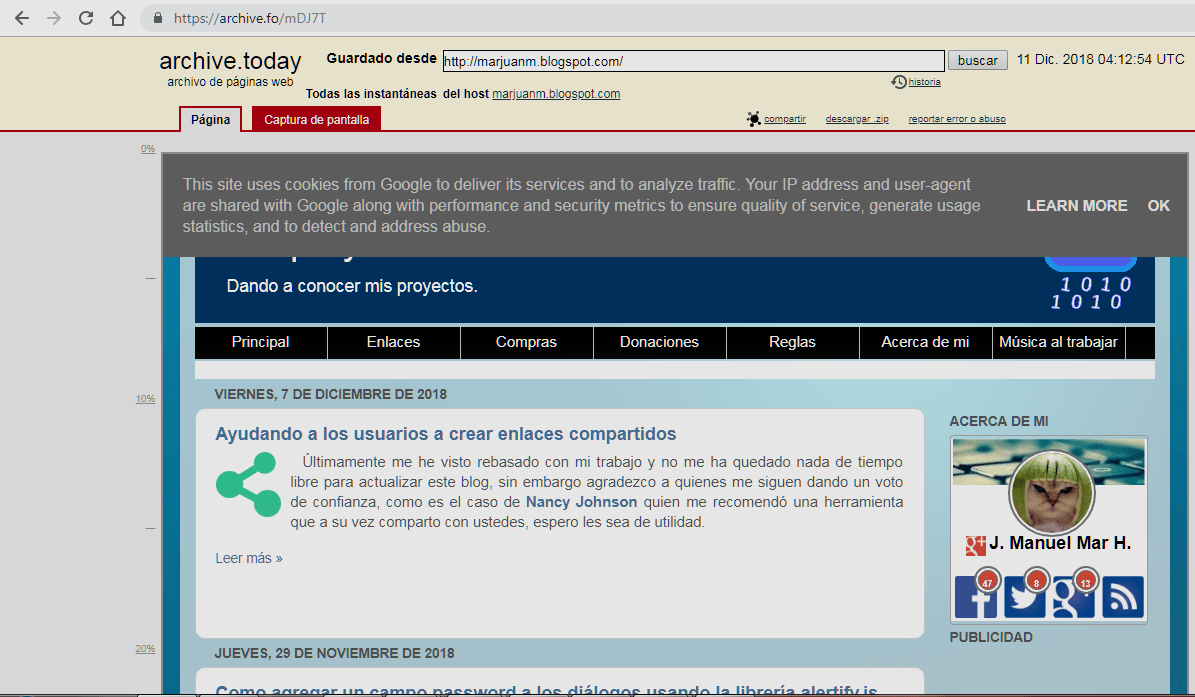
Si presionamos el enlace "Todas las instantáneas del host marjuanm.blogspot.com" veremos que se ha indexado de nuestro sitio web.
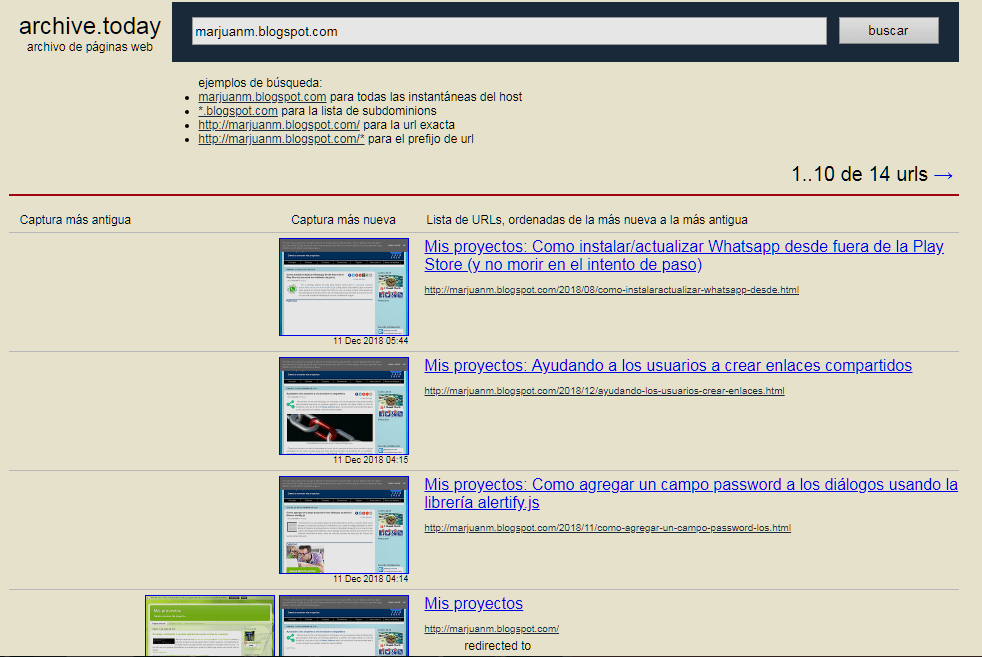
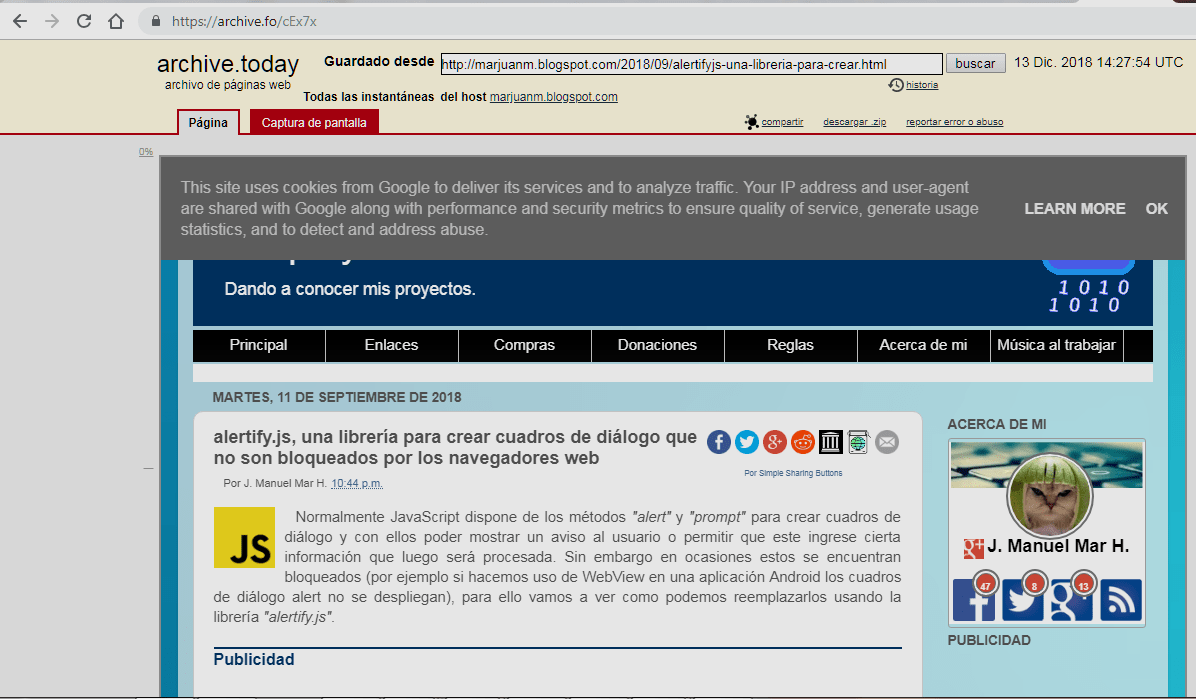
Solo catorce documentos indexados, repito, pasa muy pocas veces por lo que deja mucho que desear, regresaremos a nuestra web principal con el botón "Atrás" de nuestro navegador web y haremos clic sobre el mismo artículo "alertify.js, una librería para crear cuadros de diálogo que no son bloqueados por los navegadores web".
OOPS!!!!, archive.today no nos direcciona a la versión archivada sinó al artículo del blog directamente, ¿y porqué es esto?, pues porque no se encuentra en su base de datos y en lugar de ello nos direcciona al artículo directamente, pero nosotros queremos ver como se veía el artículo para esa fecha (11 de septiembre de 2018) y si no está indexarlo, ¿cómo podemos hacerlo?.
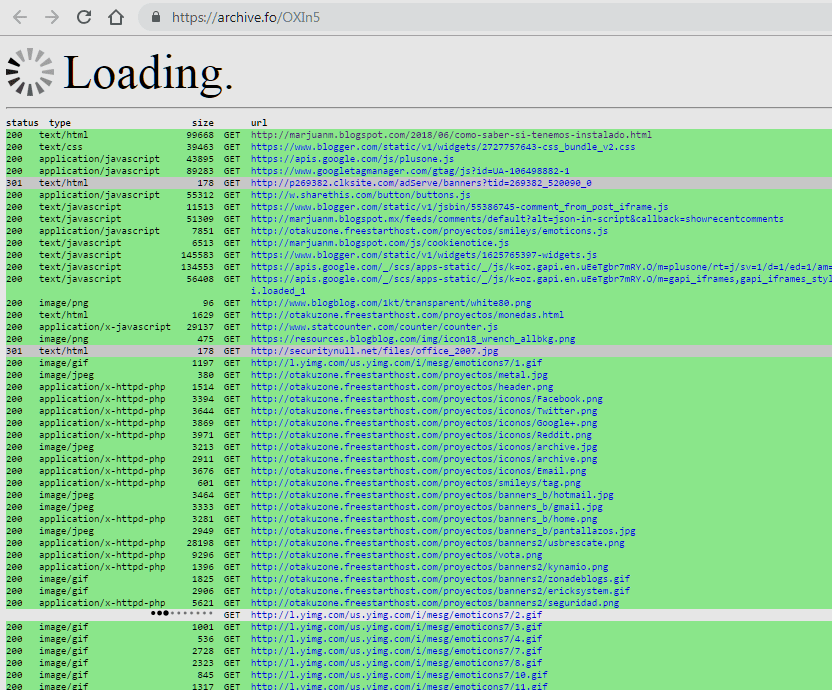
Abriremos en nueva pestaña o ventana del navegador la dirección web https://archive.ph/ y en la primer área de búsqueda ingresaremos el URL a indexar (http://marjuanm.blogspot.com/2018/09/alertifyjs-una-libreria-para-crear.html) y presionaremos el botón "Archivar".
Veremos una pantalla como la siguiente, archive.today está indexando ese artículo y a continuación nos enviará al archivo ya indexado.
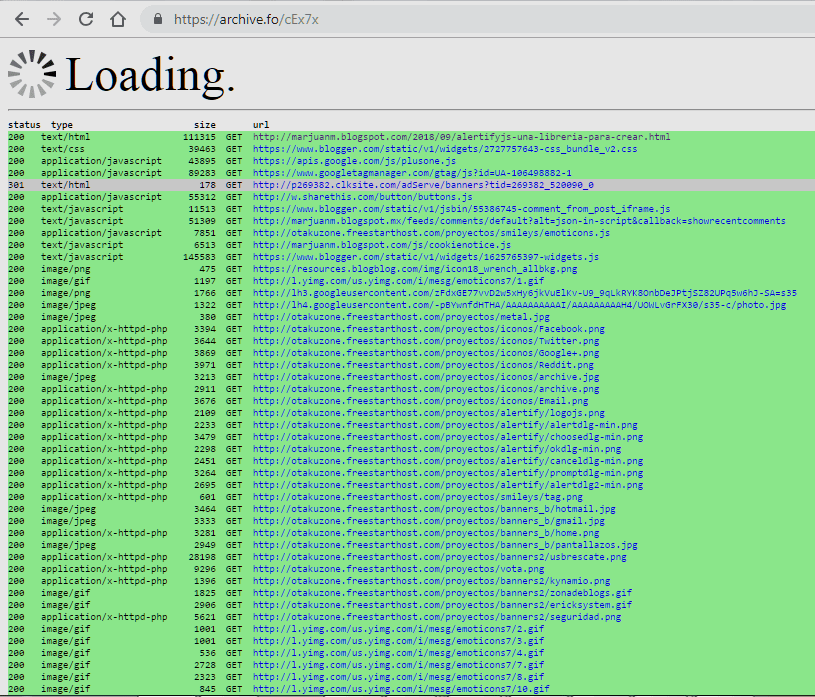
De nuevo, ya somos parte de la historia. Ahora iremos a ver todo el histórico de nuestro sitio web:
Como podemos ver, ya nuestro artículo forma parte de archive.today, el problema es que el indexado automático es extremadamente lento, prácticamente tendremos que ir agregando los artículos uno por uno (Wayback machine también tiene ese problema), además en comparación con Wayback machine no podremos agregar los artículos faltantes al vuelo, sinó que hay que ir a la página web del proyecto e irlos anexando.
Ahora que entendemos como trabajan estos dos servicios vamos a ver la manera de agilizar el indexado de los mismos.
El siguiente script nos permitirá agregar una barra social a nuestros artículos, permitiendo que los navegantes si les gustó lo compartan en las redes sociales o lo agreguen al histórico de Wayback machine o archive.today y así el artículo se conserve para siempre (o por lo menos mientras existan dichos servicios), aunque en lo personal pienso que es mejor nosotros mismos una vez redactado el artículo solicitar el indexado.
Una vez ya redactado nuestro artículo cambiaremos a la vista HTML del mismo (esto puede variar dependiendo del sistema de blog que tengamos, en el caso de un servidor ya lo integró a la plantilla de blogger por lo que aparece automáticamente para todos los post) y donde queramos que aparezca la barra social escribiremos lo siguiente:
<table border='0'>
<tr>
<td valign='top'><a href='#' onclick='window.open('https://www.facebook.com/sharer/sharer.php?u=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Share on Facebook'><img alt='Share on Facebook' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Facebook.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://twitter.com/intent/tweet?text=' + encodeURIComponent(document.title) + ':%20' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Tweet'><img alt='Tweet' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Twitter.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://plus.google.com/share?url=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Share on Google+'><img alt='Share on Google+' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Google+.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('http://www.reddit.com/submit?url=' + encodeURIComponent(document.URL)); return false;' target='_blank' title='Submit to Reddit'><img alt='Submit to Reddit' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Reddit.png' width='24'/></a></td>
<td valign='top'><a href='#' onclick='window.open('https://web.archive.org/save/' + document.URL); return false;' target='_blank' title='Submit to Internet archive'><img alt='Submit to Internet archive' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/archive.jpg' width='24'/></a></td>
<td valign='top'><a href='#' onclick='javascript:addtoarchive(); return false;' title='Submit to archive.today'><img alt='Submit to archive.today' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/archive.png' width='24'/></a></td>
<td valign='top'><a href='mailto:?body=Dando%20a%20conocer%20mis%20proyectos:%20http%3A%2F%2Fmarjuanm.blogspot.mx' target='_blank'><img alt='Send email' height='24' src='http://otakuzone.freestarthost.com/proyectos/iconos/Email.png' width='24'/></a></td>
</tr>
<tr>
<td align='right' colspan='5' valign='top'>
<a href='https://simplesharingbuttons.com/' target='_blank'><font style='font-size: 8px;'>Por Simple Sharing Buttons</font></a>
</td>
</tr>
</table>
<script language='JavaScript'>
function addtoarchive()
{
document.archive.url.value = document.URL;
document.archive.submit();
}
</script>
<form action='https://archive.ph/submit/' method='post' name='archive' style='display: inline;' target='_blank'>
<input name='url' type='hidden' value=''/>
</form>
El funcionamiento es bastante simple, es una tabla donde cada celda representa un servicio que nos permitirá compartir el enlace, siendo el orden el siguiente:
- Google+
- Wayback
- archive.today
Mediante el parámetro document.URL pasaremos el URL o dirección del artículo actual, por lo que funcionará para cualquier artículo donde lo coloquemos, como opcional algunos servicios nos permiten agregarle un título personalizado al artículo a compartir, usaremos document.title para ello en el formato del enlace para usarse.
Sin embargo a diferencia de los servicios anteriores, archive.today no pasa el URL a indexar por el método GET, es decir formando parte del enlace que bien pudiera copiarse y pegarse en el navegador web, sinó por el método POST, por lo que hay que integrar un formulario oculto en el script, llenarlo al presionar el botón compartir y luego enviarlo mediante una función JavaScript.
Esta función se activará al presionar el botón compartir de archive.today
function addtoarchive()
{
document.archive.url.value = document.URL;
document.archive.submit();
}
</script>
Dicha función rellena el campo "url" del formulario con el URL del artículo a compartir y luego envía el contenido del formulario.
<form action='https://archive.ph/submit/' method='post' name='archive' style='display: inline;' target='_blank'>
<input name='url' type='hidden' value=''/>
</form>
Así podemos hacer que los artículos compartidos se anexen a la base de datos de archive.today. Ahora vamos a verlo en acción:
Cuando ya tenemos nuestra barra social esta lucirá de la siguiente manera:

Abriremos un artículo de nuestro blog que se supone no está indexado en ninguno de los dos servicios, en este caso es el artículo "Como saber si tenemos instalado Microsoft Office usando VB.Net" http://marjuanm.blogspot.com/2018/06/como-saber-si-tenemos-instalado.html.
Presionaremos el botón agregar que corresponde al servicio de Wayback machine, se abrirá una nueva página web donde el servicio nos confirma que está agregando nuestro artículo a su base de datos. Es todo, ya tenemos ese artículo indexado.
Haremos lo mismo con archive.today. Presionaremos el botón que corresponde a este servicio, una vez presionado veremos la confirmación de que nuestro artículo está siendo indexado.
Ya está, ya nuestro artículo forma parte de la base de datos de archive.today y cuando visitemos el archivo histórico debe visualizarse (desde archive.today no desde nuestro blog) sin problemas.
Conclusiones:
Se agradece mucho que existan este tipo de servicios pues muchas veces nos traerá bonitos recuerdos ver como eran nuestros trabajos incluso a una década de haberlos concluidos (y si no hicimos una copia de seguridad ahora es el momento). En el caso de Wayback machine se sostiene por donaciones voluntarias, por lo que si nos sobra un poco de dinero sería un buen gesto hacerles una donación, los invito a que lo hagan.
En el caso de archive.today es por financiamiento privado, pero también aceptan donaciones voluntarias, por lo que si desean también pueden donar algo de dinero.
¿Te gustó este post?, entonces si lo deseas puedes apoyarnos para continuar con nuestra labor, gracias.
En el caso de archive.today es por financiamiento privado, pero también aceptan donaciones voluntarias, por lo que si desean también pueden donar algo de dinero.
Procedencia de las imágenes:
|
File: Imagen de relojes Pixabay bajo licencia Creative Commons
El resto de las imágenes corresponden a los servicios de Wayback machine y
archive.today respectivamente.
|





No hay comentarios. :
Publicar un comentario